
「ゼミのDXを進めたい」第2弾、今回は公開されている言語地図データをGoogle My Maps上に表示する方法をシェアします。言語地図を参照する機会が多いけれど、アイコンと形式を対照させながら分布を確認するのが少し面倒だなぁという方は是非やってみてください。手順の紹介は「言語地図をGoogle My Mapsに表示する手順」からなので、時間の無い方はそこまで飛ばしてください。
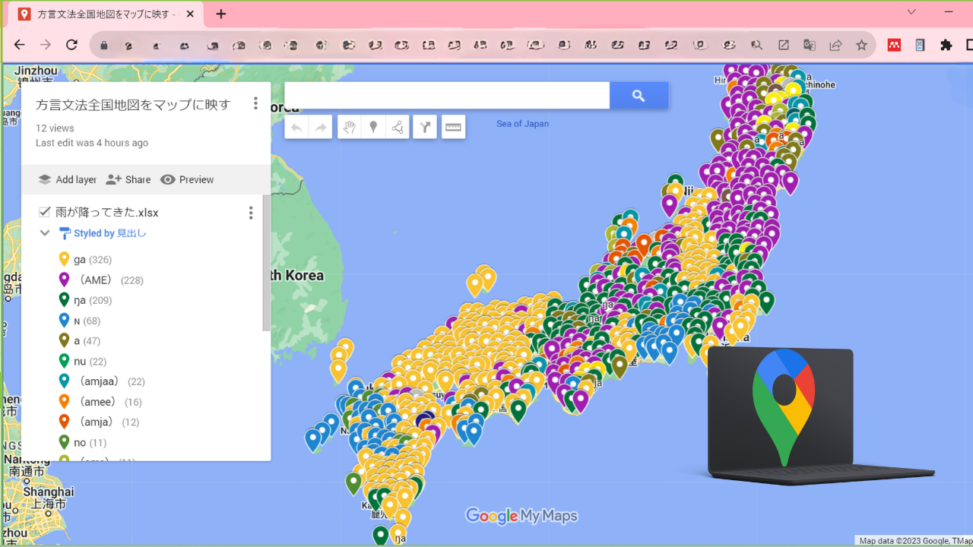
はじめに、この記事を読めば最終的にこんなものが作れるよ~というものを載せておきます。
言語地図をMy Mapで開く | Google My Maps
目次
言語地図
言語地図とはどのような語形や発音がどこに現れるかを項目ごとにアイコンを付したり、等語線を引くなどして表した地図のことです。国語研による『日本言語地図』や『方言文法全国地図』など現在では非常に多くの言語地図が公開されています※。
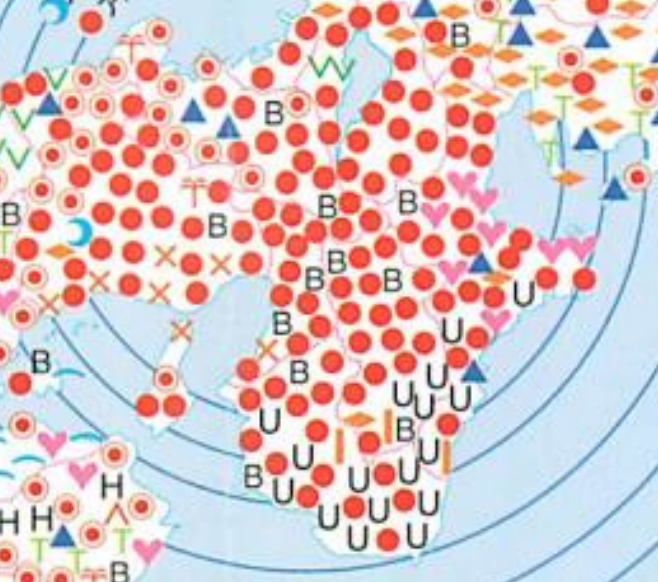
非常に有名な例に全国アホ・バカ分布図というものがあります。これは朝日放送の「探偵ナイトスクープ」に依頼のあった、「東京からどこまでが『バカ』で、どこからが『アホ』なのか調べてください」という質問に答えるべく、番組が総力をあげて調査を行ったものです。放送後は松本修プロデューサーが研究を引き継ぎ調査結果を地図にまとめて報告しています(松本 1993)。ここでも画像のように語形にアイコンを与えて、地図上にプロットしています。

このように、言語地図は語形の分布を分かり易く示してくれる便利なアイテムですが、語形の種類が多かったり、アイコンの形が似通っていたりするとその分布を確認するのにかなり注意を要することがあります。ここで断っておきますが、似た語形に似たアイコンを与えて分布を見えやすくするということ自体は言語地図の作成において非常に重要なことです。ただ、そのような図は単純にいくつかの語形を取り立ててその分布や報告を確認したい場合には不向きだということです。
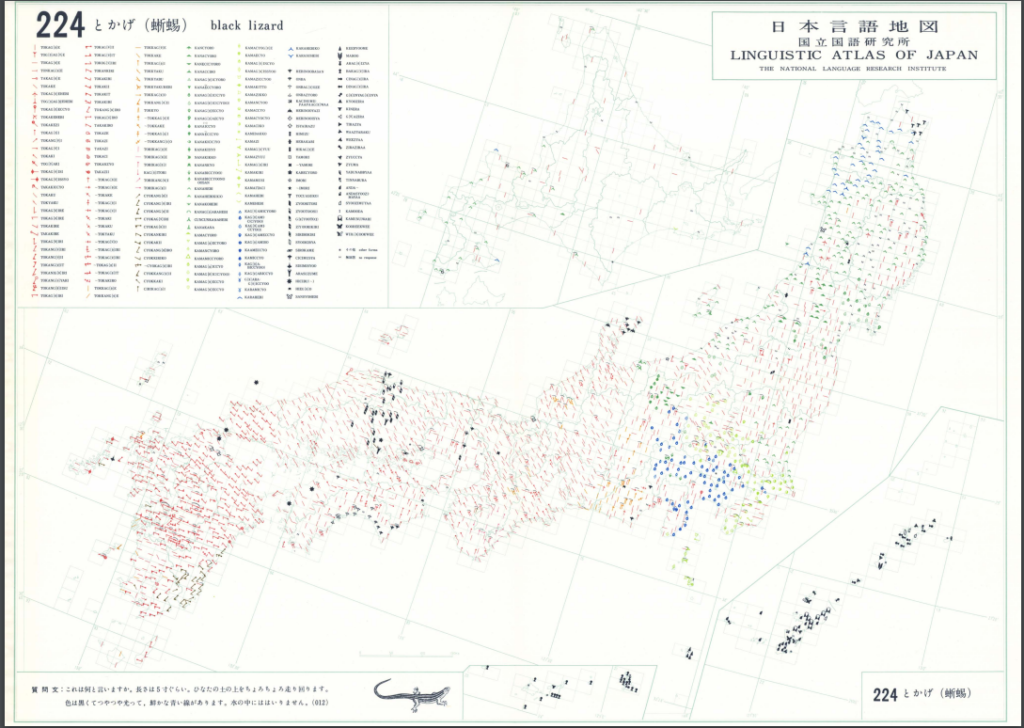
例えば下の画像は『日本言語地図地図 第5集』に含まれる「とかげ(蜥蜴)」の分布図です。非常に多くの語形を似た色や語形によって分類していて、全体の傾向を確認しやすい地図になっています。しかし、例えば自分の住む地域で使われている語形が、他にどこの地域で使われているのかを確認するような用途にはあまり向きません。凡例から語形に対応したアイコン見つけて、地図上からそのアイコンを一つ一つ探し出すのはかなり面倒ですし、ほとんどの場合見落としが起こります。

そういう用途を行う場合には地図ではなく、元データ(xls形式でダウンロード可能)をダウンロードして、見出し語にフィルターを設定して検索するとよいでしょう。このままでも地点コードや座標情報を確認できるので、自分の住む地域で使われている語形が、他にどこの地域で使われているのかを調べることは一応達成できますが、しかし、やはり地図に比べるとどこの地域で使われているのかが分かりにくいですね。
そういう訳で選択した語形をハイライトしてくれるような地図が作れると一番いいなぁと思う訳です。
※このほかにも様々な言語地図があり、国語研の「言語地図データベース」などによって検索することができます。
Google My Maps
Google My Mapsとは地図上に任意の地点やルートをプロットして自分だけの地図を作成できるサービスです。
単にマーカーを追加するだけでなく、車や自転車のルートを書き込んだり、エリアの長さや面積を測ったりなど、本当に色んなことができるのですが、今回大事なのは座標情報を含んだCSVやspreadsheetなどのファイルを元にレイヤーを作成できる機能です。言語地図のような膨大な地点を持つレイヤーを手動で導入するには途方もない苦労が必要で現実的ではないですが、この機能のおかげでダウンロードしてきたxlsファイルをそのまま使って簡単に地図を作成することが出来るわけです。
具体的には読み込んだCSVやspreadsheetから、座標情報が含まれる列とタイトルとする列を設定するだけで後は自動で地点をプロットしてくれます。また地点をグループ化する機能もあるため語形ごとに同じ色のアイコンを与えてグループ化することもできます。
言語地図をGoogle My Mapsで開く手順
それでは、実際に言語地図をGoogle My Maps のレイヤーとして表示してみましょう。
①言語地図をダウンロードする
まずは座標情報を持った言語地図のデータをダウンロードしましょう。どれでもよいのですが、今回は『日本言語地図』の「とかげ(蜥蜴)」のデータを使います。『日本言語地図』の地図データ(pdf)はこちらから、経緯度の情報付きの元データ(xls)はこちらからダウンロードできます。
②データを編集する
データをエクセルなどで開いて編集しましょう。この段階で必要に応じて不要なデータを削除したり、データを並び替えておけば更に用途にあった地図を作成することができます。
今回は以下の処理をしておきましょう。次節で詳しく述べますが、Google My Mapsの仕様によるデータの取りこぼしを防ぐためのものです。データが不完全でもよいからとりあえずGoogle My Mapsで表示する方法を体験したいという方は飛ばしていただいても構いません。
- データの並び替え
- ファイルの分割
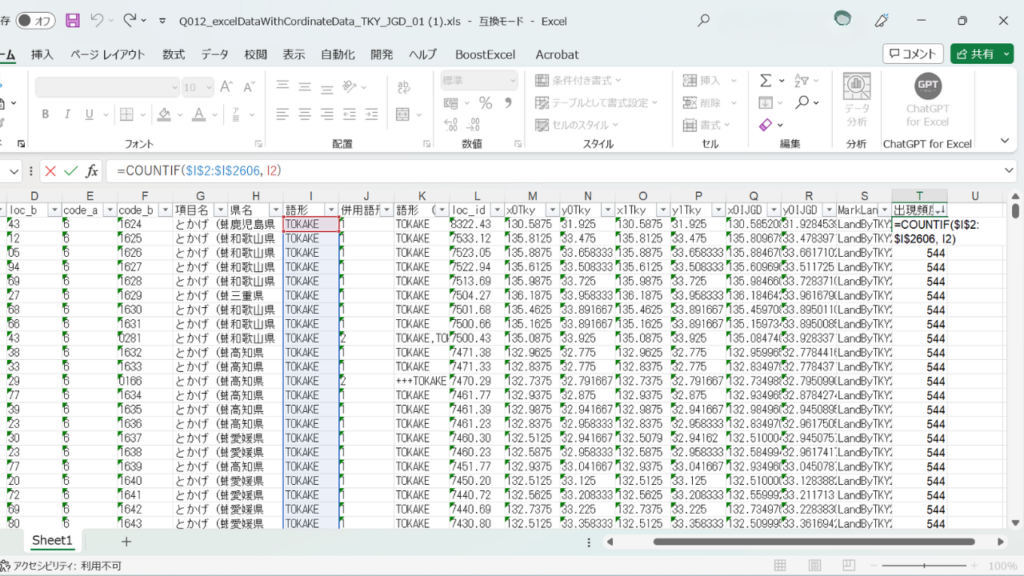
まずは1.データの並び替えです。各地点のデータをその語形の出現頻度にっよって並びかえます。データが出現頻度順に並べばどんな方法でもよいのですが、今回はCOUNTIF関数とフィルター機能を使って並び替えました。
//凡例。範囲は絶対参照にしておくこと。 =COUNTIF(範囲:語形の列全体, 検索条件:その行の語形) //記事と同じデータなら、これをT2セルに打ち込んで、フィルハンドルで一番下までコピーすればOK! =COUNTIF($I$2:$I$2606, I2)
次に、ファイルの分割です。Google My Mapsは一つのレイヤーに2000の地点しか持つことができないので、2000を越えるデータは分割して別のレイヤーとして導入する必要があります。そこで2000番から後のデータは新しいエクセルファイルを作ってそこにコピーしましょう。ここで、同じ語形なのに別々のグループとして扱われることになってしまうことを防ぐために。ファイルの区切りが同一の語形のデータの間に来ないように注意しましょう。
今回のデータでは語形の出現頻度(降順)で並べて、2000番目に来るデータの語形は「TOKKAG〔N*〕E」ですが、前後のデータの語形も「TOKKAG〔N*〕E」です。ここで区切ると「TOKKAG〔N*〕E」が誤って二つの別グループとして扱われてしまうので、今回は少し戻って1991番目のデータを区切りとしましょう。ここは「TOKAG〔g〕II」と「TOKKAG〔N*〕E」の区切り目です。
こうして、1番目から1991番目までのデータを含むエクセルファイルと1992番目から2606番目までのデータを含むエクセルファイルを用意するわけです。
③Google My Mapsにインポートする
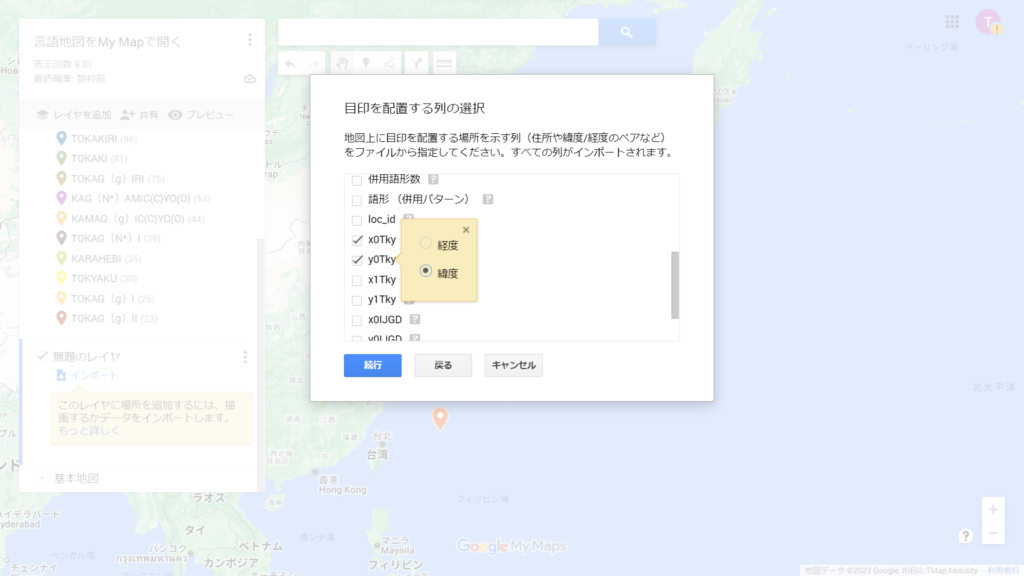
それでは遂に準備したファイルをGoogle My Mapsにインポートしましょう。任意のマイマップに新しいレイヤーを追加して、「インポート」をクリック、①、②で作成したファイルを一つ選択します。すると、先頭の行を勝手に列の見出しとして読み込んでくれて、どの列に座標情報が含まれるのか、どの列の情報をマーカーのタイトルにするのかを聞いてきます。今回はx0IJGDを経度、y0IJGDを緯度、語形をタイトルに設定しましょう※。すると少ししたら、全ての地点がマップにプロットされます。
②でデータを複数のファイルに分割している場合は、更に新しいレイヤーを作り、再度同じ手順で2つ目以降のファイルをインポートしましょう。
※『日本言語地図』の経緯度の情報付きのデータで使用できる座標情報は日本測地系(x0Tkyとy0Tky)、海部に落ちた一部地点を便宜的に移動したもの(x1Tkyとy1Tky)、世界測地系:JGD2000(x0IJGD、y0IJGD)の3種類があります。どれを使用してもあまり結果は変わりませんが、xが経度でyが緯度であることは間違えないようにしましょう。
④語形によってグループ化する
ここまででもとりあえず、地点と語形はプロットされている訳ですが、全ての地点と語形に同じアイコンが付与されているのでとっても見にくいですね。そこで語形によって地点をグループ化してみましょう。
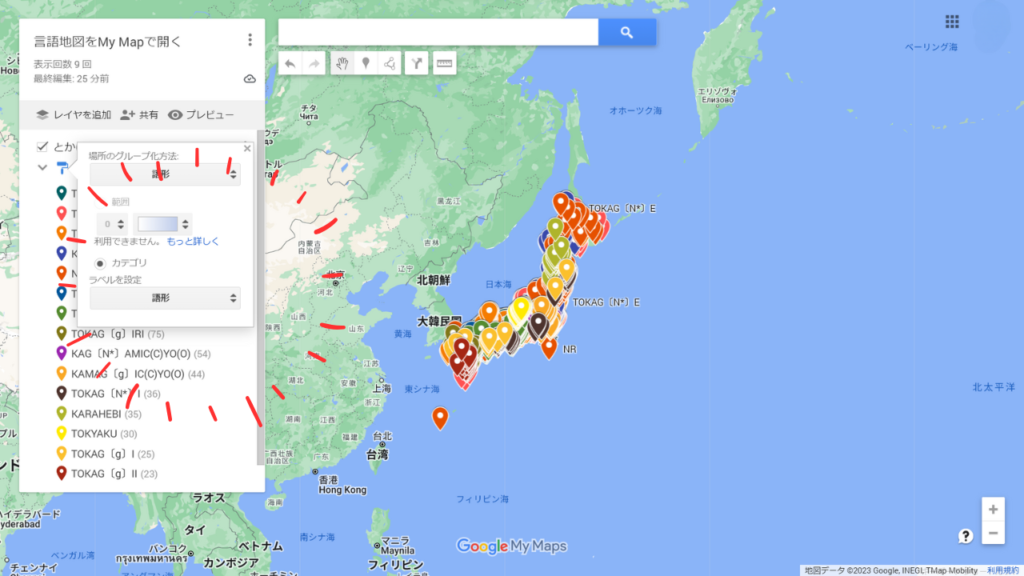
レイヤーのタイトルすぐしたの「スタイル」をクリック、「場所のグループ化方法」と「ラベルを設定」どちらも「語形」を選択します。すると語形によって各地点が色分けされます。
⑤完成
これで完成です。レイヤ選択画面で語形の数を確認できますし、取り上げたい語形を選択したら、その語形を持つ地点がハイライトされます。また、メニュー(地図のタイトル横の縦向きの3点リーダー︙をクリックすると出てくる)を開くと、作成した地図をKMLとしてエクスポートしたり、埋め込みコードを発行したりすることなどができます。
この記事の初めの地図の埋め込みコードもGoogle My Mapsによって書き出したものです。
今回の方法の限界
ここまで、言語地図をGoogle My Maps のレイヤーとして表示する方法を紹介してきたわけですが、実は今回の方法には限界というか欠点がいくつかあります。(詳しい対策について「終わりに」を参照)
一つ目は語形同士の類似性を表わさないということです。今回の方法では一つ一つの語形に単純に個別のアイコン(個別の色)を与えているだけなので、語形同士の類似性を示すことはできません。互いに似ている語形に全く違う色が与えられたり、かなり異なる語形同士によく似た色が与えられたりしてしまう訳です。
二つ目はGoogle My Mapsの仕様によるもので、一つのレイヤーでは2000個以上の地点、20種類以上のグループを扱うことができないというものです。今回扱った「とかげ(蜥蜴)」のデータも実際には2605地点あるのですが、何も編集しないままだとGoogle My Mapsでは2000地点までしか表示されません。また語形は元の地図では224のグループに分類されていますが、Google My Mapsでは20グループまでしか表示されず、それ以外は全て「その他」のグループにまとめられてしまいます。
この問題に対する簡単な対策が今回紹介した予め語形の出現数の多い順に並べ替えておいて、2000を越えるデータは分割して別のレイヤとして導入するするという方法です。これによって元データに含まれていた地点が消えてしまうということは防ぐことができます。しかし、この場合でも語形のグルーピングはそれほど多くすることができず、多くのものが「その他」に分類去れてしまいます。また、いちいち別のファイルに分割しないといけないということも少々面倒くさいです。
以上のように、Google My Mapsは非常に易しく便利な反面、高度なカスタマイズやグループ分けはできないという欠点があります。
終わりに
以上、言語地図をGoogle My Maps のレイヤーとして表示する方法を紹介しました。前述したようにこの方法には欠点もいくつかあるのですが、用途によっては単純に地図のpdfファイルを眺めるよりも随分使い勝手がよいと思います。また、そもそもGoogle My MapsはGoogle Driveに保存されるものですので、共有や公開がとっても簡単にできるという点もメリットだと言えるでしょう。
また、その欠点についても前述した単純な方法以外にも様々な対策が考えられます。まず一つ目については、例えば元データを編集する段階でクラスター分析を行った適切なラベルを振り、Google My Maps上でそのラベルを元にグループ化して表示すればある程度解決することができるでしょう。(K-means clusteringなどの単純なクラスター分析はお手元のExcelで比較的簡単に実装することができます。)また二つ目については、Google My MapsのページのUI設計に関わる問題なので、APIを使って独自のマップを作り、自分のページに埋め込むなどすれば解決できそうです。
今後もGoogle My Mapsを使って色々試してみたいなと思っています。進捗は随時共有していこうと思いますので、是非ご覧ください。
参考文献
松本修(1993)『全国アホバカ分布考-はるかなる言葉の旅路-』太田出版(現在は新潮文庫)